Due to the real impact on customer lives, employee morale and investor return, the decisions of Artificial Intelligence Machine Learning models, that are developed by our bank, needs to align with our corporate goals, values and vision to enable the aspirations of our customers through prudent, accessible and fair financial solutions. Our advisors and client service teams need to be able to trust that the recommendations and summaries that are output by our generative and decision models aligns with our moral and privacy guidelines for the ethical application of Artificial Intelligence in delivering financial solutions to a global reach of clients, companies and governments. As such we need to be vigilant to recognize risks in our Machine Learning Development pipeline that may show up as biased decisions in ML due to the real impact on customer lives, employee morale and investor return, the decisions of Artificial Intelligence Machine Learning models, that are developed by our bank, needs to align with our corporate goals, values and vision to enable the aspirations of our customers through prudent, accessible and fair financial solutions. Our advisors and client service teams need to be able to trust that the recommendations and summaries that are output by our generative and decision models aligns with our moral and privacy guidelines for the ethical application of Artificial Intelligence in delivering financial solutions to a global reach of clients, companies and governments. As such we need to be vigilant to recognize risks in our Machine Learning Development pipeline that may show up as biased decisions in ML model performance and how to prevent and mitigate these outputs where bias can enter through source data, representation bias, measurement bias, learning bias, aggregation bias, evaluation bias, and deployment bias.
We have terabytes of inhouse unstructured data, gathered across seventy decades of banking operations in multiple jurisdictions, to draw on in building high performing deep neural networks and algorithms for our machine learning models using best practice advantages of Machine Learning Operations (MLOps). Leveraging MLOps will help us to minimize risks and bias that are inherent as a result of change in data over time that varied depending on the market segments that change over time; financial regulations and laws that vary over decades, and financial products and services that increasingly converged to intelligent technology platforms. We need to be aware of risks in how we pose solutions in the application of this data. The data is shaped by historical variances as it was created and gathered across timelines where society norms, government laws and business practices was measurably shaped by events we may now look at as just or unjust.
As such, if building a model that includes data from a time in history where segregation and redlining (preventing certain neighborhoods based on demographics from accessing mortgages) was normal, this would lead to bias output of machine learning models to gain the risk compounded insights, elevation of immoral patterns with the continuation of decisions that perpetuate low levels of lending, that results in representational bias that impacts marginalized groups and areas. So the context of our training data matters to ensure representation as well as correct labelling of data to mitigate allocative wrongs that result from historical bias. As machine learning is statistical driven from data we need to design functions that learn from the data to limit the impact of tripping on bias in different parts of the Machine Learning development cycle from data curation, development of the model through training and testing, to deployment.
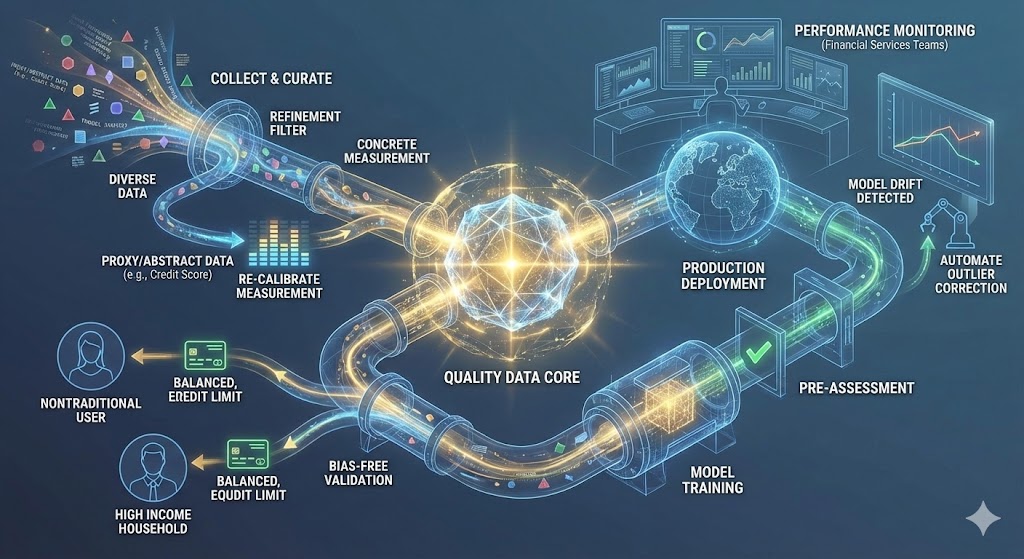
Quality Data is the core of our ML models and key to ensuring performance accuracy as we go through the complex cycle of MLOps in collecting and curating data, provide our model training, pre-assess it for deployment, and if found to meet bias free and validation goals deployed to the world for production. For example, in our credit card product line, any ML Model to decide credit limits will need data preparation that accounts for measurement bias, a proxy for concrete measurement, such as abstract credit score, in such a way that it harms nontraditional users of credit as their measurement may be systematically lower for credit than high income households. Critical stages follow the tail-end of the MLOps process to managing the efficacy of the model through deployment and after, to monitor production performance of the model by user populations in internal businesses included but not limited to financial data services teams. We also need to assess for model drift where we automate tasks to look for outliers and any change in accuracy of the model to generalize solutions over time as new data is produced.
We’ll optimize our ML development process to avoid learning bias which can take place when we select a performance model that optimizes the performance metrics we set but also results in objectives that cause disparate impact with unfair decisions that results from minimizing measurements that is traditionally expressed by marginalized groups. These groups will then find that, as production users of our model, production results do not speak to them. As such, we will need to monitor development of our models to avoid excess pruning that leads to disparities and structured exclusion to generalized solutions that runs counter to the intent of our models to serve diverse global private, public and institutional clients.
Our AI ML Model structure will need to include automated agents that monitor the performance of our models and trigger retraining with latest data and humans in the loop to evaluate and interpret AI output along the ML data gathering, development, deployment and iterative intents to improve and update the model for continued applicability in production. As we bring ML models and deep learning frameworks to the forefront of business operations, we’ll ensure that the deployment stage does not use narrow benchmarks to measure model performance, for example a client investment app that can be leveraged by multiple lines of business. We want the benchmark to be built across a wide range of large and small cap stocks and not a subset of the markets top performers to prevent the continued concentration of funds in a few large companies. This will enable clients that want to invest in green companies or organic producers to get ML recommendation for representation of those companies in their portfolio.
One of the most important steps we can take is to keep humans in the loop as knowledge experts in data used to train models, task said persons with the review and certification of ML decisions to prevent deployment bias or automated decision making that exacerbates the application of stereotypes that results from bias data and learning models. Over time, data change and models performance can grow in inaccuracy as new data come that is different from the data on which the AI’S algorithmic functions were built. As such, our Machine Learning Development cycle will need to include monitoring and retraining of ML models while looping through the iterative steps of working our framework to identify potential biases in measurement, representation, aggregation, deployment stages of building and promotion our learning model to new versions of release that are fit for production model performance and how to prevent and mitigate these outputs where bias can enter through source data, representation bias, measurement bias, learning bias, aggregation bias, evaluation bias, and deployment bias.


